Introduction to AI¶
What is Artificial Intelligence?¶
For spatial decision-makers, Artificial Intelligence is best understood not as science fiction or automation hype, but as a new type of analytical capability.
Traditional GIS systems execute instructions written by humans. AI systems, in contrast, learn patterns from examples and apply those patterns to new data.
This distinction changes how systems are built, validated, and managed.
Intelligence in Humans vs Machines¶

Human intelligence in mapping relies heavily on:
- Visual pattern recognition
- Contextual understanding
- Experience-based judgment
An experienced image analyst can look at satellite imagery and immediately recognize:
- Buildings vs rocks
- Roads vs dry riverbeds
- Cropland vs fallow land
This ability comes from learning through exposure over time.
AI attempts to replicate one narrow aspect of human intelligence:
The ability to recognize patterns from examples.
However, AI systems differ from humans in important ways:
| Humans | AI Systems |
|---|---|
| Learn from few examples | Need many examples |
| Use contextual reasoning | Rely on statistical patterns |
| Can adapt quickly to new scenes | Struggle outside training conditions |
| Explain reasoning intuitively | Often act as “black boxes” |
Management Implication¶
AI is not intelligent in the human sense. It is a statistical pattern learner that can scale across large datasets — but only within the limits of what it has been trained on.
Manager’s Checkpoint — Human vs Machine Intelligence¶
Before adopting AI, ask:
- Is this task based on visual pattern recognition rather than logical rules?
- Can examples of correct outputs be collected?
- Is consistency more important than human intuition?
If answers are “yes,” AI may be appropriate.
Rule-Based Systems vs Learning-Based Systems¶

Most GIS workflows are rule-based systems.
Examples:
- Select pixels where NDVI > threshold
- Buffer roads by a fixed distance
- Classify slope ranges into categories
These systems require:
- Clear rules
- Defined thresholds
- Deterministic logic
They work well when the problem is:
- ✔ Structured
- ✔ Physically measurable
- ✔ Expressible in equations or conditions
But many mapping problems are not easily expressible as rules.
Example:
“How do we write rules that define what a building looks like in every city, roof type, and lighting condition?”
This is where learning-based systems become useful.
Instead of defining rules manually, we provide:
- Examples of buildings
- Examples of non-buildings
The system learns distinguishing patterns automatically.
| Rule-Based GIS | Learning-Based AI |
|---|---|
| Logic defined by experts | Patterns learned from data |
| Transparent decision steps | Statistical internal representation |
| Good for structured problems | Good for complex visual patterns |
| Hard to scale to visual tasks | Scales well once trained |
Management Implication¶
AI is not a replacement for rule-based GIS. It is an additional tool used when:
The problem cannot be reliably solved using explicit rules.
Manager’s Checkpoint — Rule vs Learning¶
Ask:
-
Can this problem be solved using clear physical or logical rules?
-
If yes → Use traditional GIS.
-
Does the task depend on visual or contextual interpretation?
-
If yes → Consider AI.
Artificial Intelligence as Pattern Recognition¶

At its core, AI for geospatial applications is:
Pattern recognition applied to spatial data
It does not “understand” cities, forests, or roads. It identifies statistical similarities between pixels, textures, shapes, and spectral signatures.
For example, a building detection model learns:
- Rectangular shapes
- Edge patterns
- Spectral contrast between roofs and surroundings
It then applies this learned pattern to new imagery.
Why This Matters for Managers¶
AI performance depends on:
- How representative the training data is
- Whether new areas look similar to training areas
- How consistent imagery conditions are
If the environment changes significantly, AI may fail — even if it worked well elsewhere.
Strategic Perspective¶
AI works best when:
- ✔ Patterns are consistent
- ✔ Large volumes of data need interpretation
- ✔ Manual mapping is repetitive
AI struggles when:
- ❌ Rare or unusual features are important
- ❌ Contextual understanding is required
- ❌ Data differs greatly from training samples
Manager’s Checkpoint — AI as Pattern Recognition¶
Before approving an AI project, ask:
- Are the features visually consistent across regions?
- Can we collect enough examples for training?
- What happens if the landscape looks different than training data?
These questions determine whether AI is a strategic fit or a risky investment.
1.3 What is Machine Learning?¶
Machine Learning (ML) is the practical engine that enables most modern AI systems. For geospatial managers, ML can be understood as a method that allows computers to learn decision logic from data instead of relying only on rules written by experts.
In a GIS context, traditional workflows depend on explicitly defined thresholds, overlays, and conditions. Machine learning, in contrast, builds its own internal rules by analyzing examples where the correct answers are already known.
This shift changes project planning: instead of asking “What rule should we write?”, the key question becomes “Do we have enough reliable examples for the system to learn from?”
1.3.1 Learning from Examples Instead of Rules¶

In rule-based GIS, experts translate their knowledge into explicit instructions. For example, a land cover classification rule might rely on spectral thresholds, vegetation indices, or elevation ranges.
Machine learning reverses this workflow.
Instead of defining the rule, we provide:
- Input data (e.g., satellite imagery, elevation, indices)
- Correct outputs (e.g., labeled land cover classes)
The system then analyzes many examples and discovers statistical relationships that distinguish one class from another.
From a management perspective, this means:
- Expertise shifts from writing rules to designing good training data
- The quality of results depends heavily on how representative and accurate the examples are
- The model may identify patterns that are not obvious to human analysts
This approach is powerful for complex visual problems where rules would be too numerous, fragile, or location-specific.
Manager’s checkpoint:
- Do we have historical or manually interpreted data that can serve as examples?
- Does the problem involve variability that is hard to capture with fixed thresholds?
- Are we prepared to invest effort in preparing high-quality labeled datasets?
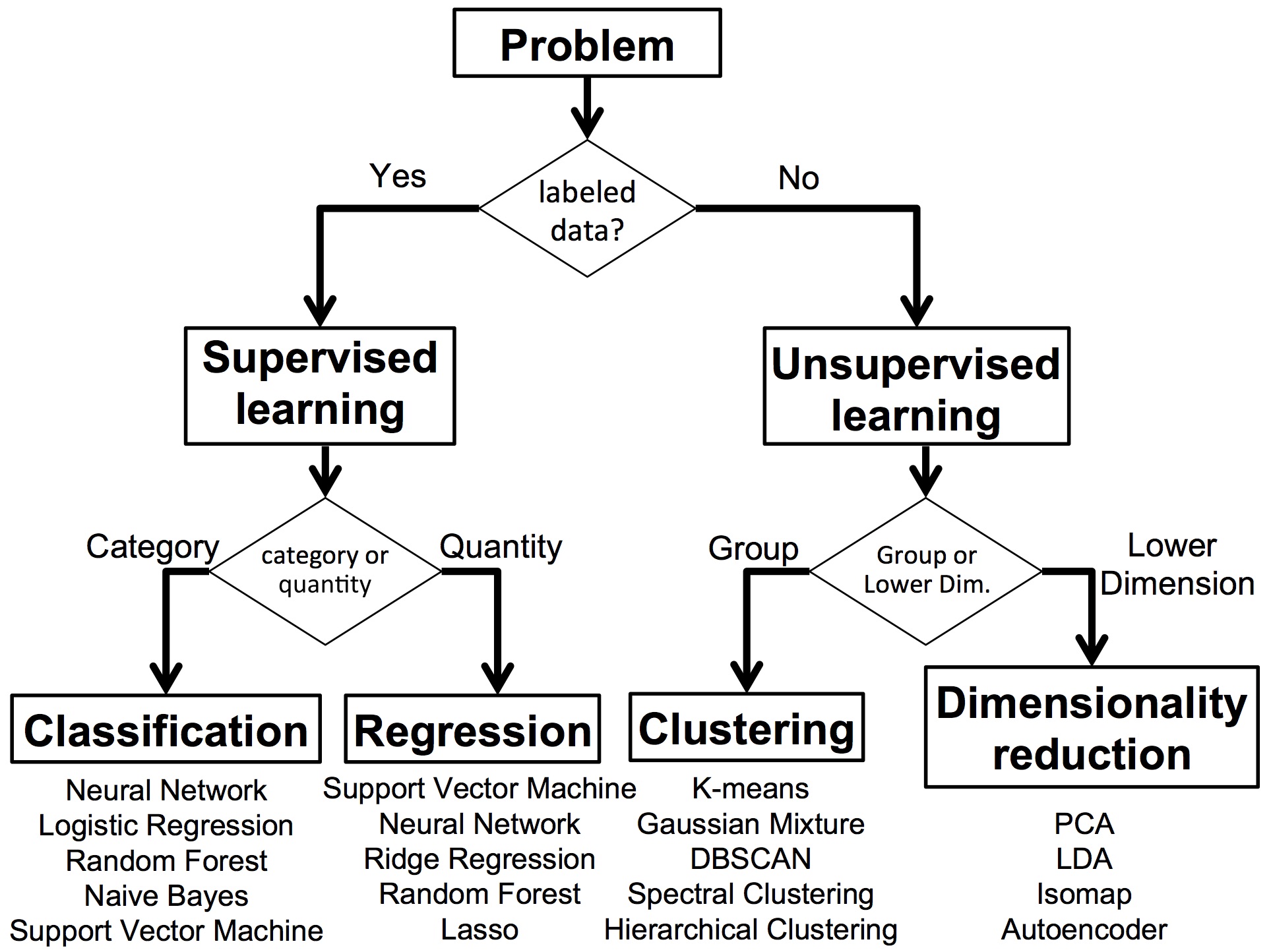
1.3.2 Supervised vs Unsupervised Learning (Conceptual)¶

Machine learning methods are often categorized based on whether the system is given the correct answers during training.
Supervised learning uses labeled examples. Each input is paired with a known output, such as:
- Satellite pixels labeled as forest, water, or urban
- Image patches labeled as building or non-building
The system learns to map inputs to known categories. Most operational GeoAI applications — such as feature extraction, land cover mapping, and object detection — use supervised learning.
Unsupervised learning, on the other hand, does not use predefined labels. Instead, the system groups data based on similarities. For example, it might cluster areas with similar spectral signatures without knowing what those clusters represent.
From a management viewpoint:
| Aspect | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Requires labeled data | Yes | No |
| Output categories predefined | Yes | No |
| Operational use in mapping | Common | Limited |
| Role in projects | Production mapping | Exploratory analysis |
Supervised learning is usually the main approach when the goal is to produce operational map layers. Unsupervised methods are more useful for exploring patterns, detecting anomalies, or preparing data for further analysis.
Manager’s checkpoint:
-
Do we need specific, predefined classes in the output map?
-
If yes, supervised learning is required.
-
Is the goal exploratory analysis rather than a production layer?
-
If yes, unsupervised methods may help.
1.3.3 Training, Models, and Inference¶

A typical machine learning workflow in geospatial projects has three main stages: training, model creation, and inference.
Training is the stage where the system analyzes labeled examples and adjusts its internal parameters to reduce errors. This process can be computationally intensive and may require specialized hardware or cloud platforms.
The model is the result of training. It is a mathematical representation of the patterns learned from the data. For managers, the model is the asset that can be reused to process new imagery.
Inference is the stage where the trained model is applied to new, unseen data to produce outputs such as classified maps, detected features, or prediction layers.
Key management implications:
- Training is a one-time (or periodic) investment; inference is the routine operational step
- If input data characteristics change significantly (sensor, resolution, geography), retraining may be required
- Model performance must be evaluated using data that was not used during training
This separation helps in planning budgets and timelines. Training phases require more technical effort and resources, while inference phases focus on large-scale production.
Manager’s checkpoint:
- Do we understand the difference between building the model and using it operationally?
- Is there a plan for validating the model on independent data?
- How often will retraining be needed as new data becomes available?
1.4 What is Deep Learning?¶
Deep Learning is a specialized branch of machine learning designed to handle highly complex data, especially images, audio, and text. In geospatial applications, it has become the dominant approach for analyzing satellite and aerial imagery at scale.
While traditional machine learning relies on manually designed input features (such as indices, texture measures, or statistics), deep learning systems learn these features automatically from raw data. This ability makes them particularly powerful for tasks like building extraction, road detection, and land cover mapping.
For project managers, deep learning represents a shift toward higher performance on complex visual tasks, but also toward greater data, computing, and validation requirements.
1.4.1 Neural Networks in Simple Terms¶

Deep learning systems are built using structures called neural networks. These are computational models inspired loosely by how the human brain processes signals.
A neural network is organized in layers:
- An input layer that receives data (for example, pixel values from an image)
- Multiple hidden layers that transform the data through learned mathematical operations
- An output layer that produces predictions (such as class labels or segmentation masks)
Each layer detects increasingly abstract patterns. Early layers may identify edges or color contrasts. Deeper layers combine these patterns to recognize shapes, textures, and object-like structures.
From a management perspective, the key idea is not the mathematics but the capability:
Neural networks can automatically discover useful patterns in raw imagery without requiring experts to manually define every feature.
Manager’s checkpoint:
- Is the task visually complex, involving shapes, textures, or context?
- Would manual feature design be difficult or unreliable? If yes, neural network–based methods may be appropriate.
1.4.2 Why Deep Learning Works Well for Images¶
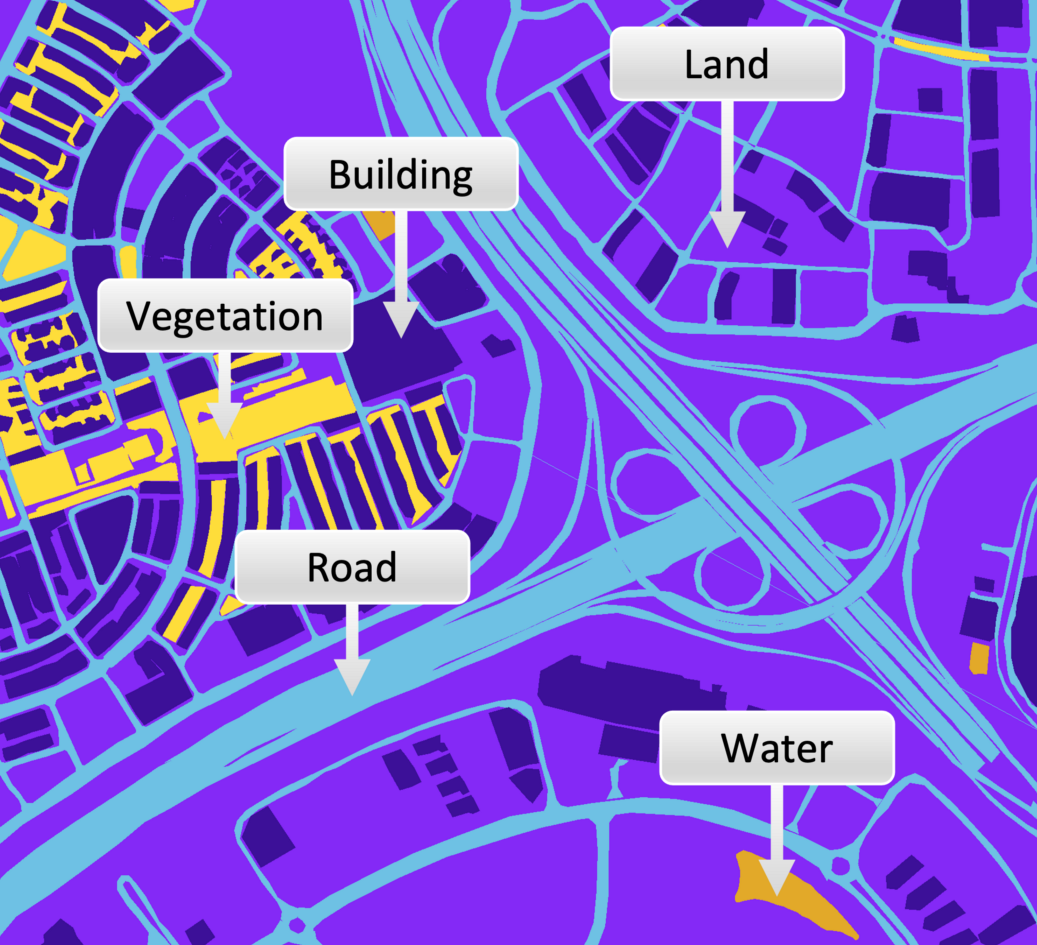
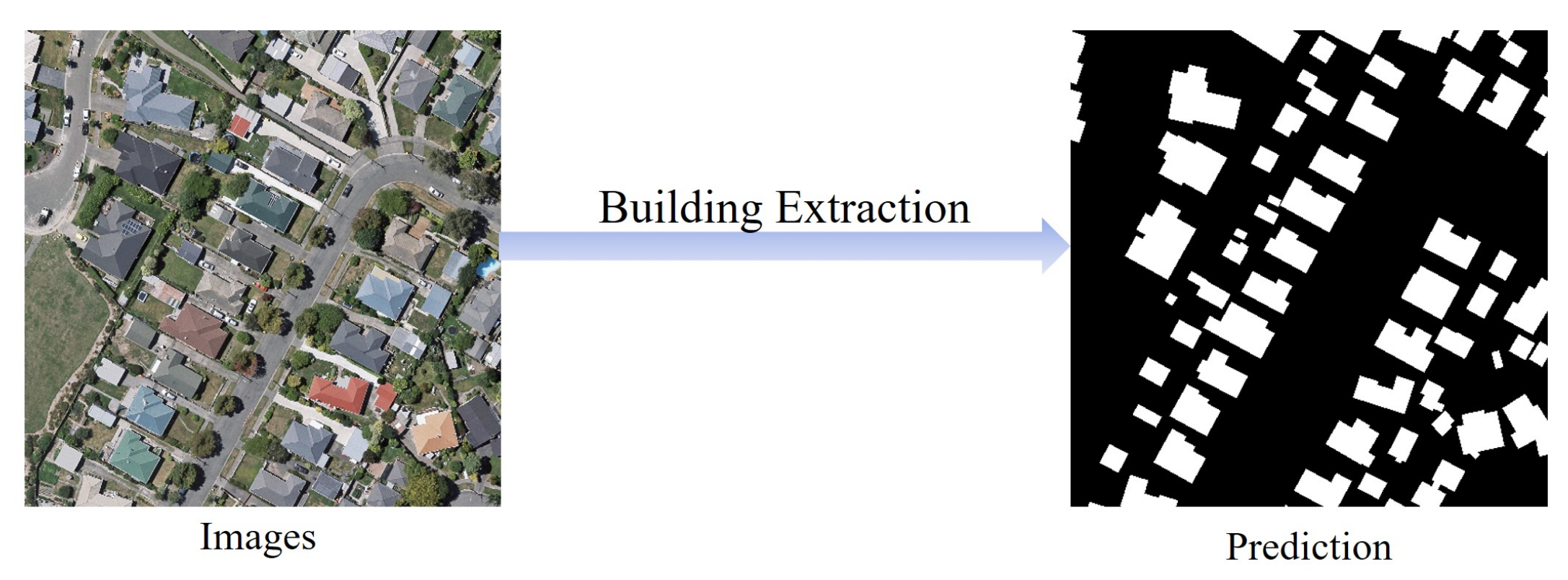
Images contain large amounts of spatial detail and subtle variation. Traditional methods often struggle to capture this complexity using simple thresholds or handcrafted features.
Deep learning models, particularly Convolutional Neural Networks (CNNs), are designed to process images in a way that preserves spatial relationships between pixels. They can learn:
- Edges and boundaries
- Repeating textures (such as rooftops or vegetation patterns)
- Spatial arrangements (for example, the rectangular layout of buildings)
This makes deep learning well suited for:
- Feature extraction from high-resolution imagery
- Land cover and land use classification
- Object detection (buildings, vehicles, infrastructure)
- Semantic segmentation (pixel-level mapping)
However, performance depends strongly on:
- Large volumes of labeled training data
- Consistent image quality and resolution
- Computational resources for training
Manager’s checkpoint:
- Do we have enough labeled examples across different environments?
- Are imagery characteristics consistent across the project area?
- Is the expected accuracy improvement worth the additional cost and complexity?
1.4.3 Deep Learning vs Traditional Machine Learning¶
Both traditional machine learning and deep learning are tools for learning from data, but they differ in how they handle input information.
Traditional machine learning methods, such as Random Forest, typically require structured inputs. Analysts must design and compute features beforehand — for example, spectral indices, texture measures, or statistical summaries.
Deep learning, by contrast, works directly with raw inputs such as image pixels. It automatically learns the features that are most useful for the task.
| Aspect | Traditional ML | Deep Learning |
|---|---|---|
| Input data | Precomputed features | Raw data (e.g., pixels) |
| Feature design | Manual, expert-driven | Automatic, learned by model |
| Data requirement | Moderate | Large |
| Computing requirement | Lower | Higher |
| Performance on imagery | Limited for complex patterns | Strong for complex visual tasks |
From a management viewpoint, the choice is strategic:
Traditional ML may be sufficient when:
- Data volumes are smaller
- Problems are well structured
- Computational resources are limited
Deep learning is more appropriate when:
- Tasks involve complex visual interpretation
- Large labeled datasets are available
- High accuracy at scale justifies higher resource investment
Manager’s checkpoint:
- Is the problem mainly image-based and visually complex?
- Do we have the data and infrastructure to support deep learning?
- Would simpler methods meet operational accuracy requirements?